
18/06/22
A Meta-Analysis of Decentralized Storage Technology
Category
Written by
Read time
41 min
Decentralized Storage Landscape
Unlike Layer1 blockchains in which the primary purpose is trustless value transfers, such as Bitcoin and Ethereum, decentralized storage networks need not only record transactions (which are used for storage requests) but must also ensure that data is stored for a specific amount of time as well as overcome other challenges pertaining to storage. As a result, it is not uncommon to see decentralized storage blockchains applying multiple consensus mechanisms that work in tandem to ensure different aspects of the storage and retrieval can work.
In below non-exhaustive list of decentralized storage projects, we can catch a glimpse of the decentralized storage landscape as well as niche data storage use cases, such as P2P filesharing and data markets.
The focus of this research is on storage networks (IPFS and non-IPFS based).
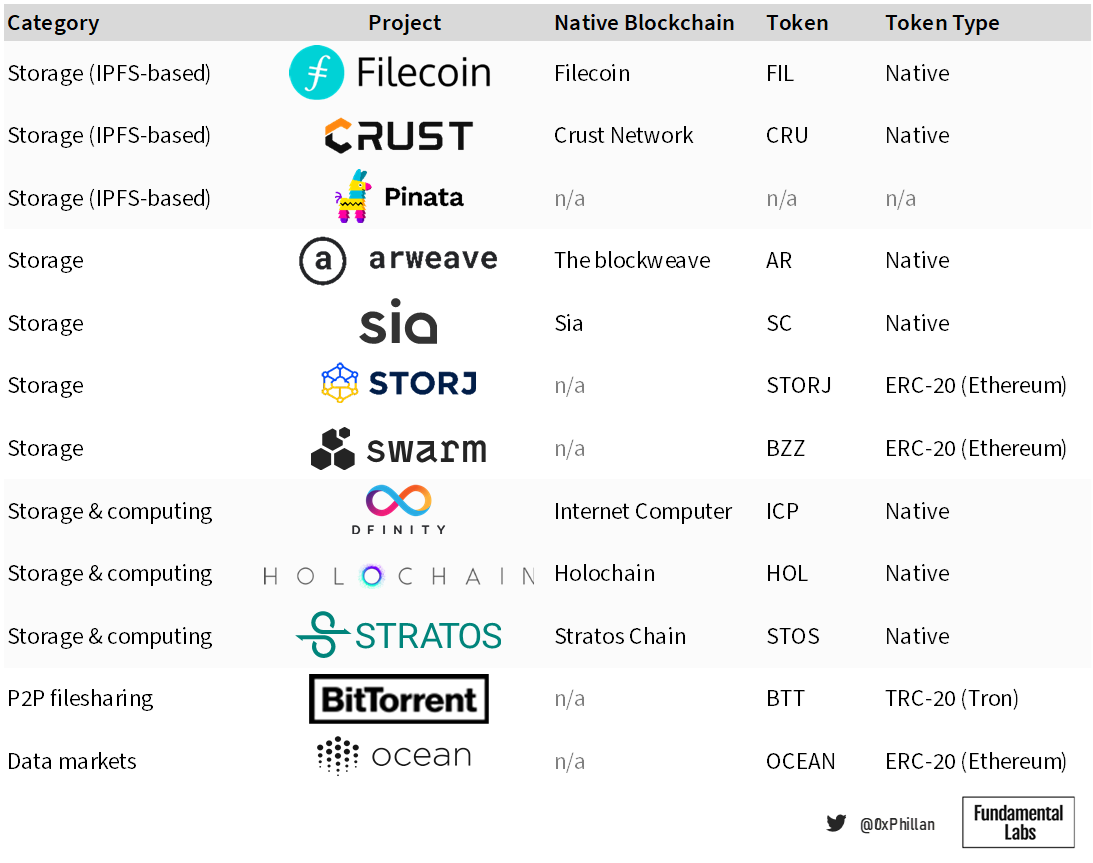
Decentralized Storage Design Challenges
As has been demonstrated in the first section of this paper, blockchains are not suitable for storing large amounts of data on-chain, due to the cost associated with it and the impact on block space. As a result, decentralized storage networks must apply other techniques to ensure decentralization. Not using the blockchain as the primary storage space, however, leads to a long list of other challenges if the network wants to maintain decentralization.
In essence, a decentralized storage network must be capable of storing data, retrieving data, and maintaining data while ensuring that all actors within the network are incentivized for the work they do, while also upholding the trustless nature of decentralized systems.
Hence, from a design perspective, we can summarize the primary challenges in below illustrative paragraphs:
Data Storage Format – First the network must decide how to store the data: should the data be encrypted and should the data be saved as a full set or split into smaller pieces.
Replication of Data – Then the network needs to decide where to store the data: how many nodes should the data be stored on, and whether all data is to be replicated to all nodes or whether each node should get different fragments to further protect data privacy. The data storage format and the network diffusion of data will determine the probability of data being available on the network with regards to devices failing over time (durability).
Storage Tracking – From here, the network needs a mechanism to track where the data is stored. This is important, because the network needs to know which network locations to ask to retrieve specific data.
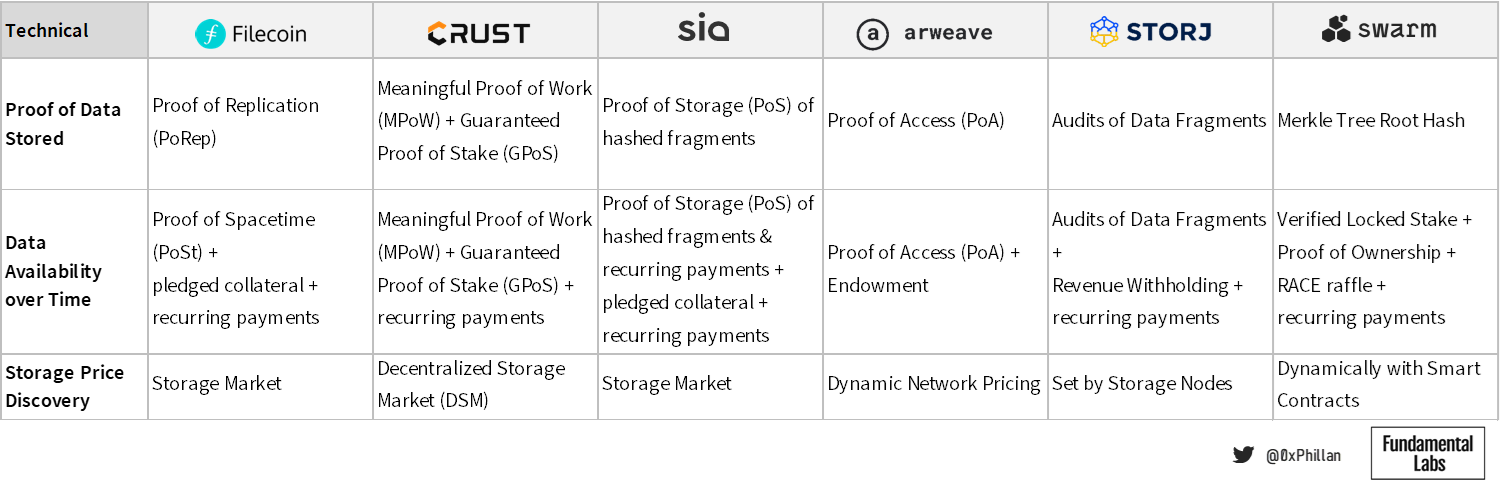
Proof of Data Stored – Not only does the network need to know where data is stored, but storage nodes also need to be able to prove that they are indeed storing the data they are intended to be storing.
Data Availability over Time – Networks also need to ensure data is where it is meant to be when it is meant to be there. This means mechanisms must be designed to ensure nodes do not remove old data over time.
Storage Price Discovery – And nodes expect to be paid for the on-going storage of files.
Persistent Data Redundancy – While networks need to know where data is located, by nature of public open networks nodes will continually leave the network and new nodes will continually join the network. Hence, apart from ensuring a single node is storing what they are meant to be storing when they are meant to be storing it, the network needs to ensure that when a node leaves and its data disappears, sufficient copies of the data or data fragments are maintained across the network.
Data Transmission – Then, when the network connects to nodes to retrieve data that is requested (by a user or for data maintenance workloads), the nodes that are storing the data must be willing to transmit the data, as bandwidth also comes at a cost.
Network Tokenomics – Finally, apart from ensuring that data resides within a network, the network must ensure that the network itself will be around for a long time. If the network were to disappear, it would take all data with it – hence strong tokenomics are necessary to ensure network permanence, and thus data availability, over the long term.
Overcoming Challenges of Data Decentralization
In this section, I compare and contrast various aspects of decentralized storage network design of IPFS, Filecoin, Crust Network, Arweave, Sia, Storj, and Swarm and how they overcome the aforementioned challenges. This reflects well-established as well as up-and-coming decentralized storage networks that use a wide range of technologies to achieve decentralization.
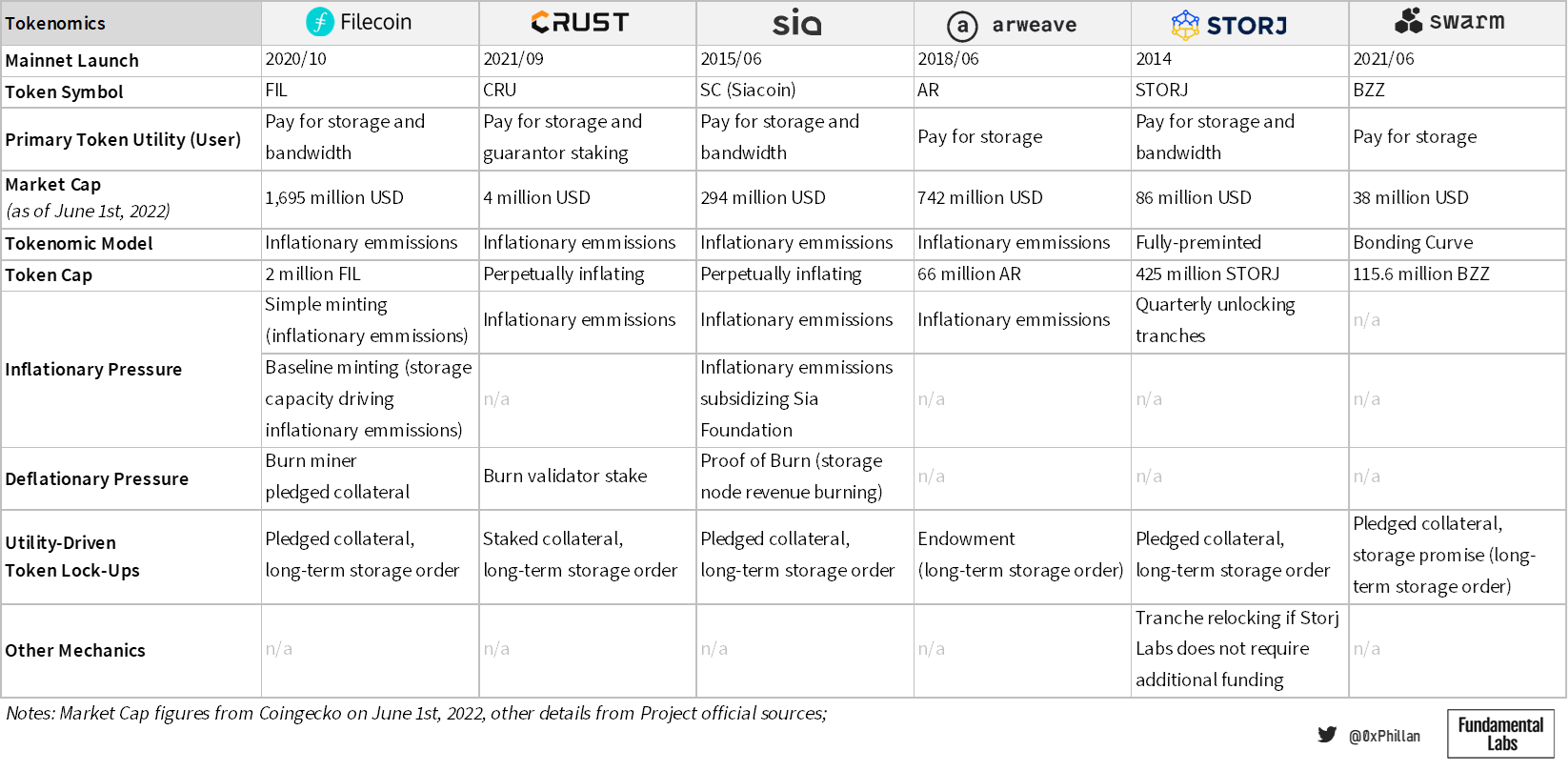
Below tables summarize both technical aspects and tokenomics of each network, that will be covered in greater detail throughout this section, as well as what the writer believes are strong use cases of these chains following their various design-elements.
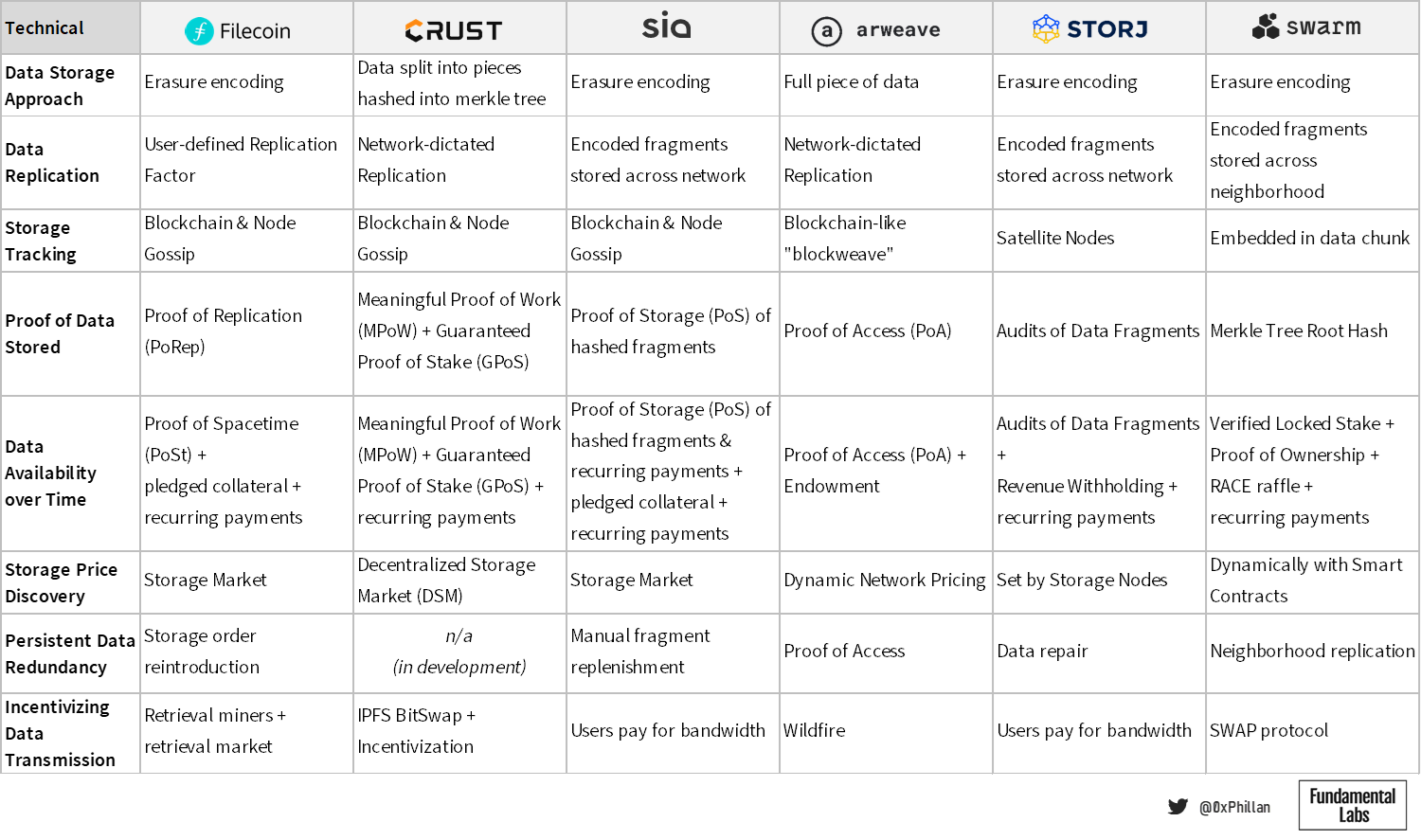

Due to many concepts being closely interlinked within each protocol design, it is not possible to clearly split out each challenge, hence there is some overlap between sub-sections.
Data Storage Format and Replication of Data
Data format and the replication of data refers to how data is stored on a single node instance, and how data is spread across multiple nodes when a user or application requests to store a file (henceforth users and applications will be collectively referred to as users or clients). This is an important distinction, as data can also be stored on a node as a result of data maintenance procedures initiated by the network or other network actors.
In below table we can see a brief overview of how the protocols store data:

From the above projects, Filecoin and Crust use the Interplanetary File System (IPFS) as the network coordination and communication layer for transmitting files between peers and storing files on nodes. IPFS and Filecoin were both developed by protocol labs.
When new data is to be stored on the Filecoin network, a storage user must connect to a storage provider through the Filecoin storage market and negotiate storage terms, before placing a storage order. The user must then decide which type of erasure encoding (EC) is to be used and the replication factor thereof. With EC, data is broken down into constant-size fragments, which are each expanded and encoded with redundant data, so that only a subset of the fragments are required to reconstruct the original file. The replication factor refers to how often the data should be replicated to more storage sectors of the storage miner. Once the storage miner and the user agree on the terms, the data is transmitted to a storage miner and is stored in a storage miner’s storage sector.
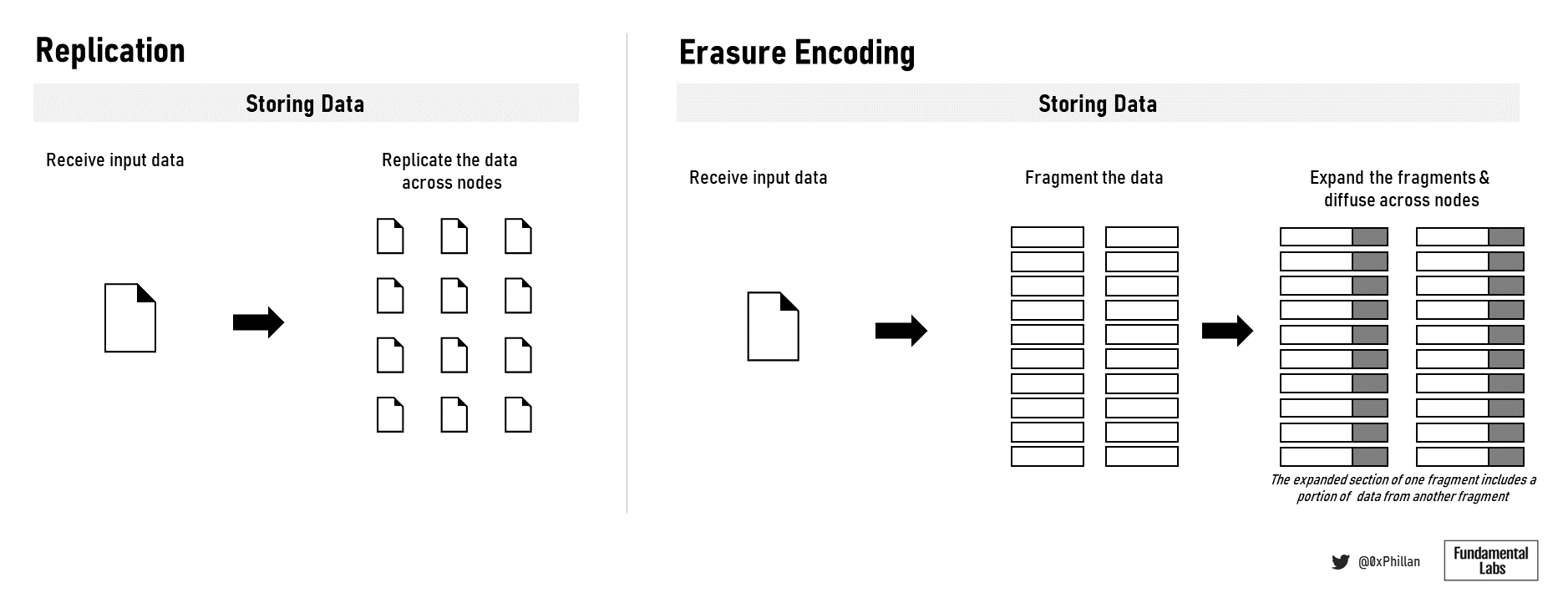
If users want to further increase redundancy, they need to engage in additional storage deals with additional storage providers, as there still exists the risk that one storage miner goes offline and with it all of their pledged storage sectors. Applications such as NFT.Storage and Web3.Storage built by Filecoin on the Filecoin protocol solve this by storing files with multiple storage miners, however at a protocol level users must manually engage with multiple storage miners.
In contrast, Crust replicates data to a fixed number of nodes: when a storage order is submitted the data is encrypted and sent to at least 20 Crust IPFS nodes (the number of nodes can be adjusted). On each node the data is split into many smaller fragments which are hashed into a Merkle tree. Each node keeps all fragments that make up the full file. While Arweave also uses replication of full files, Arweave takes a somewhat different approach. After a transaction is submitted to the Arweave network, first one single node will store the data as a block on the blockweave (Arweave’s manifestation of a blockchain). From there a very aggressive algorithm called Wildfire ensures the data is replicated to rapidly across the network, because in order for any node to mine the next block, they must prove they have access to the previous block.
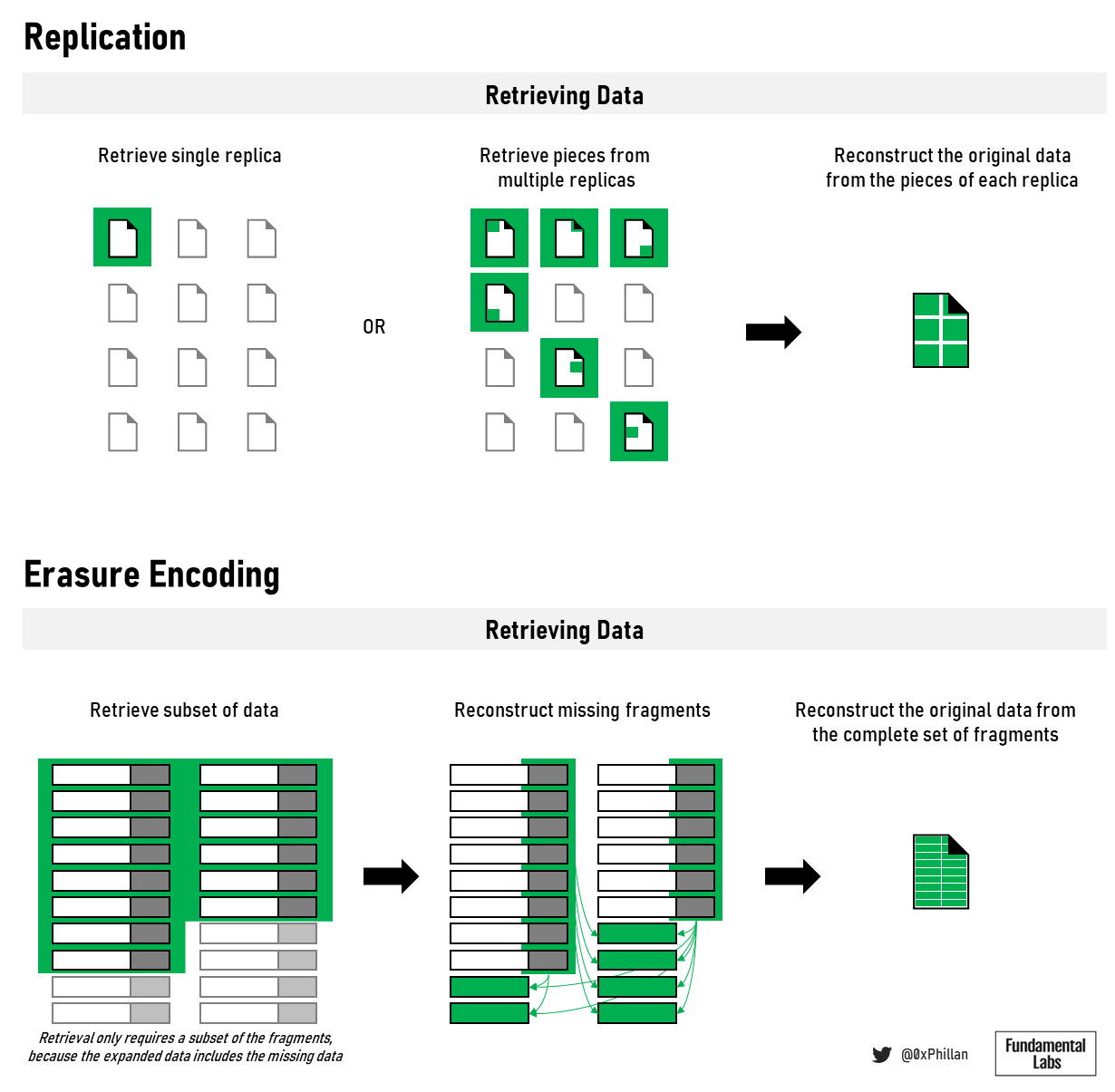
Sia, Storj, and Swarm use erasure encoding (EC) to store files. With Crust’s implementation, 20 full data sets are stored across 20 nodes. While this is extremely redundant and makes the data highly durable, this is highly inefficient from a bandwidth perspective. Erasure encoding presents a much more efficient means of achieving redundancy, by improving data durability without a large bandwidth impact.
Sia and Storj directly propagate EC fragments to a specific number of nodes to meet certain durability requirements. Swarm, on the other hand, manages nodes in a way that nodes that are in closer proximity form a neighborhood, and those nodes proactively share data chunks (the specific fragment format used in Swarm) among each other. If there is popular data that is being recalled from the network often, other nodes are incentivized to store the popular chunks as well – this is called opportunistic caching. As a result, in Swarm it’s possible to have a far greater number of data fragments in the network than what is considered a minimum “healthy” amount. While this does have bandwidth implications, this can be considered front-loading future retrieval requests by reducing the distance to the requesting node.
Storage Tracking
After data has been stored, either to one or many nodes, the network needs to know where the data is stored. This way when users request to retrieve their data, the network knows where to look.

Filecoin, Crust, Sia, and Arweave all use a blockchain or a blockchain-life structure to manage storage orders and keep a record of every storage request placed on the network. In Filecoin, Crust and Sia storage proofs (i.e., proof that files have been stored by a miner, are stored on chain). This allows these networks to know where which data is located at any point in time. With Arweave, the network incentivizes all nodes to store as much data as possible, however, nodes are not required to store every single piece of data. Because Arweave stores data as blocks on their blockchain and nodes are not required to store all data, nodes can be missing some data which can be retrieved at a later time. Hence why Arweave’s blockweave is a “blockchain-like” structure.
On Filecoin, Crust and Sia, storage nodes all maintain a local table with details of which storage nodes store which data. This data is regularly updated amongst nodes by gossiping amongst each other. For Arweave, however, when content is requested nodes are requested opportunistically instead of reaching out to specific nodes that are known to save the content.
Storj and Swarm both do not have their own layer 1 blockchain and hence track storage in a different way. In Storj, storage order management and the storage of files are split between two different types of nodes, namely satellites and storage nodes. Satellites, which can be a single server or a redundant collection of servers, only tracks data which users have submitted to them for storage, and only store it on storage nodes that have entered an agreement with them. Storage nodes can work with multiple satellites and store data from multiple satellites. This architecture means that in Storj to store files, no network-wide consensus is needed, which means increased efficiency and fewer computing resources are required to store data. However, this also means that if a satellite goes offline, the data managed by that satellite will be inaccessible. Hence it is recommended that a satellite be comprised of multiple redundant servers.
In Swarm, the address of data stored is directly recorded in the hash of each chunk in the data to chunk conversion process. Since chunks are stored across nodes in the same address space (i.e. neighborhood), the neighborhood of a file can be identified simply by the chunk hash itself. This means that a separate tracking mechanism of where which files are stored is not necessary, as the storage location is implied by the chunk itself.
Proof of Data Stored, Availability Over Time, and Storage Price Discovery
Apart from the network knowing where data is stored, the network must have a way to verify that the data that is meant to be stored on a specific node is indeed stored on that specific node. Only after that validation has occurred can the network employ other mechanisms to ensure that the data remains stored over time (i.e., that storage nodes do not remove the data after the initial storage operation). Such mechanisms include algorithms that prove data is stored over certain period of time, financial incentivization for successfully concluding the duration of storage requests, and disincentivization of non-completion thereof, amongst others. It should be noted here that data availability over time does not equate to permanence, although permanent storage is a form of long-term data availability. Finally, nodes expect to be paid for their storage efforts, which is reflected in the aforementioned incentivization mechanisms.
To illustrate both proof of data stored and how data availability is ensured over time, this section will look at the full storage process per protocol.
Filecoin
On Filecoin, before a storage miner can receive any storage requests, they must deposit collateral to the network which acts as a pledge to provide storage to the network. Once completed, miners can offer their storage on the Storage Market and set a price for their services. Users who want to store data on Filecoin can set their storage requirements (e.g., storage space required, storage duration, redundancy, and replication factor) and place an ask.
The Storage Market then matches the client and the storage miner. The client then sends their data to the miner, who stores the data in a sector. The sector is then sealed, which is a process that transforms the data into a unique copy of the data called a replica that is associated with the public key of the miner. This sealing process ensures that every replica is a physically unique copy and forms the basis of Filecoin’s Proof of Replication algorithm. This algorithm verifies the validity of storage proofs provided using the Merkle tree root of the replica and the hash of the original data.
Over time storage miners are required to consistently prove their ownership of the stored data by regularly running this algorithm. However, consistent checks like this require a lot of bandwidth. The novelty in Filecoin is that to prove data is stored over time and reduce bandwidth usage, the miner generates proofs of replication in sequence, using the output of the previous proof as the input for the current proof. This is executed over a number of iterations that represent the duration that the data is meant to be stored for.
Crust Network
In Crust Network nodes must also first deposit collateral before they can take storage orders on the network. The amount of storage space a node provides to the network determines the maximum amount of collateral, which is staked and allows the node to participate in creating blocks on the network. This algorithm is called Guaranteed Proof of Stake, which guarantees that only nodes that have a stake in the network can provide storage space.
Nodes and users are automatically connected to the Decentralized Storage Market (DSM) that automatically chooses which nodes to store the user’s data on. Storage prices are determined based both on user requirements (e.g. storage duration, storage space, replication factor) and network factors (e.g. congestion). When a user submits a storage order, the data is sent to a number of nodes across the network, which split the data and hash the fragments using the machine’s Trusted Execution Environment (TEE). Since the TEE is a sealed off hardware component that even the hardware owner cannot access, there is no way the node owner can reconstruct the files on their own.
After the file is stored on the node a work report which includes the hashes of the files is published to the Crust blockchain, together with the remaining storage of the node. From here to ensure data is stored over time the network regularly requests random data checks: within the TEE a random Merkle tree hash is retrieved together with the relevant file fragment, which is decrypted and re-hashed. The new hash is then compared against the expected hash. This implementation of storage proofs is called Meaningful Proof of Work (MPoW).
Sia
As is the case in Filecoin and Crust, storage nodes must deposit collateral to be able to offer storage services. On Sia, the node must decide how much collateral to post: the collateral directly impacts the storage prices for users, but at the same time posting a low collateral means the node has nothing to lose if they disappear from the network. These forces drive nodes towards an equilibrium collateral.
Users are connected to storage nodes through an automatic storage marketplace, which functions in a similar way to that of Filecoin: nodes set their storage prices, and users set their expected prices based on their target price and expected storage duration. Users and nodes are then automatically connected with each other.
After a user and nodes agree on a storage contract, the funds are locked in the contract and the data is split into segments using erasure encoding, each segment is hashed individually using different encryption keys and each piece is then replicated on several different nodes. The storage contract which is recorded on Sia’s blockchain records the agreed terms as well as the data’s Merkle tree hash. From there to ensure that data is stored for the expected storage duration, storage proofs are regularly submitted to the network. These storage proofs are created based on a randomly selected portion of the originally stored file and a list of hashes from the file’s Merkle tree that is recorded on the blockchain. Nodes are rewarded for every storage proof they can submit over time, and finally upon completion of the contract.
On Sia, storage contracts can last a maximum of 90 days. To store files beyond 90 days, users must connect to the network manually using the Sia client software to extend contracts by another 90 days. Skynet, another layer on top of Sia similar to Filecoins Web3.Storage or NFT.Storage platforms, automates this process for the user by having Skynet’s own instances of the client software execute contract renewals for users. While this is a workaround, it is not a Sia protocol level solution.
Arweave
Arweave uses a very different pricing model compared to the previous solutions, as Arweave does not allow for temporary storage: on Arweave, all data stored is permanent. On Arweave, the storage price is determined by the cost of storing data on the network for 200 years, assuming that annually those costs reduce by -0.5%. If the cost of storage reduces more than -0.5% in a year, the savings are used to append additional years of storage to the end of the storage duration. In Arweave’s own estimates, the -0.5% annual reduction in storage costs is very conservative. If reductions in storage costs are perpetually greater than Arweave’s assumption, then the storage duration will continue to grow infinitely, making the storage permanent.
The price of storing files on Arweave is dynamically determined by the network, based on the previously mentioned 200-year storage cost estimate and the difficulty of the network. Arweave is a Proof-of-Work (PoW) blockchain, meaning that nodes must solve a cryptographic hash puzzle to mine the next block. If more nodes join the network, solving the hash puzzle becomes more difficult, thus more computational resources are needed to solve the puzzle. The dynamic price-difficulty adjustments reflect the cost of the additional computational power to ensure nodes remain motivated to stay on the network to mine new blocks.
If a user accepts the price to store files on the network, nodes accept the data and write it to a block. This is where Arweave’s Proof-of-Access algorithm comes into play. The Proof-of-Access algorithm works in two phases: first, the node must prove they have access to the previous block in the blockchain, then they must prove access to another block that is selected at random called the recall block. If the node can prove access to both blocks, they enter the PoW phase. In the PoW phase only the miners that could prove access to both blocks start to try to solve the cryptographic hash puzzle. When a miner successfully solves the puzzle, they write the block – and thus the data – to the blockchain. From here, for nodes on the network to be able to mine the next block, they must include the freshly mined block. As a result, the new block and it’s data is rapidly permeated across the network.
The miner then receives transaction fees for including the data and block rewards from network token emissions. Apart from the transaction fees, the rest of the price paid by the user is stored in an endowment, which is paid out to miners that hold the data over time. This is only paid out when the network deems that transaction fees and block rewards are not enough to make mining operations profitable. This creates a float of tokens in the endowment, which further extends the 200-year minimum storage duration.
In Arweave’s model there is no tracking of storage locations. As a result, if a node does not have access to the data that is being requested, it will ask nodes in a peer list that it maintains locally for the block data.
Storj
In the Storj decentralized storage network, there is no blockchain or block-chain like structure. Not having a blockchain also means that this network does not have network-wide consensus about its state. Instead, tracking data storage locations is handled by satellite nodes, and the storage of data is handled by storage nodes. Satellite nodes can decide which storage nodes to work with to store data, and storage nodes can decide which satellite nodes to accept storage requests from.
Apart from handling the tracking of data locations across storage nodes, satellites are also responsible for billing and payment of storage and bandwidth usage to storage nodes. In this arrangement, storage nodes set their own prices and as long as users are willing to pay those prices, satellites connect them with each other.
When a user wants to store data on Storj, the user must select a satellite node to connect to and share their specific storage requirements. The satellite node will then pick out storage nodes that meet the storage requirements and connect the storage node with the user. The user then directly transmits the files to the storage nodes, while making payment to the satellite. The satellite then pays out storage nodes every month for the files held and the bandwidth used.
To ensure storage nodes are continuously storing the data fragments they are meant to be storing, satellites run regular audits on the storage nodes. The satellite, which does not store any data, selects a random piece of a file fragment before erasure encoding is applied and asks all nodes that store an erasure encoded fragment to validate the data. When sufficient nodes return data, the satellite can identify nodes that report faulty data.
To prevent nodes from disappearing and taking data offline as well as ensuring they consistently verify file fragments through audits, Storj satellites withhold large portions of storage node revenue making it financially unviable to leave the network early or to fail audits. As nodes stay in the network for longer, the proportion of withheld revenue is released. Only when a storage node determines that they want to leave the network after at least 15 months of operation and the storage node signals to the network that they want to leave the network allowing the network to move all data, does the network return remaining withheld funds.
Swarm
While Swarm does not have a layer 1 blockchain for tracking storage requests, storing files on Swarm is handled through Smart Contracts on Ethereum. As a result, storage orders with some details about the files can be tracked. And because in Swarm the address of each chunk is included in the chunk, the neighborhood of the chunk can also be identified. So, when data is requested, nodes within a neighborhood communicate with each other to return the chunks requested by the user.
Through client software, Swarm lets users determine the amount of data and duration that data is meant to be stored on Swarm and is calculated using smart contracts. When data is stored on Swarm, the chunks get stored on a node and are then replicated to other nodes in the same neighborhood as the uploading node. When the data is stored on the nodes it gets split into chunks, which map the data to a chunk tree, which builds up a Merkle tree, for which the root hash of the tree is the address that is used to retrieve the file. Hence, the root hash of the tree is proof that the file was properly chunked and stored. Every chunk in the tree further has an inclusion proof embedded, which proves that a chunk is part of a specific chunk tree and can be used as proof of custody if evidence needs to be provided that a node owns a specific chunk of uploaded data.
Nodes that want to sell long-term storage (aka promissory storage) must have a stake verified and locked-in with an Ethereum-based smart contract at the time of making their promise – essentially a security deposit. If, during the promise period, a node fails to prove ownership of the data they promised to store, they lose their entire security deposit.
Finally, to further ensure data isn’t removed over time, Swarm employs a random lottery, where nodes are rewarded for holding a random piece of data that is picked through Swarm’s RACE lottery system.
Persistent Data Redundancy
If data is stored on a certain number of nodes, it can be assumed that in the long-term as nodes leave and join the network, this data will eventually disappear. To combat this, nodes must ensure that data, in whatever form it is stored, is regularly replicated to consistently maintain a minimum level of redundancy over the user-defined storage duration.

At every block mined on the Filecoin network, the network checks that required proofs for stored data are present and that they are valid. If a certain failure threshold is crossed, the network considers the storage miner faulty, marks the storage order as failed, and reintroduces a new order for the same data on the storage market. If the data is deemed to be unrecoverable, the data is lost and the user gets refunded.
Curst Network, being the youngest network of those reviewed with a Mainnet launch in September 2021, does not yet have a mechanism to replenish file redundancy over time, but this mechanism is currently in development.
On Sia, the number of erasure encoded fragments available on the network is converted into a health indicator. As nodes and thus erasure encoded fragments disappear over time, the health of a piece of data reduces. To ensure that health remains high, users must manually open the Sia client, which checks the health status and if it is not at 100%, the client replicates the data fragments to other nodes on the network. Sia recommends opening the Sia client once a month to run this data repair process to avoid data falling below an unrecoverable threshold of fragments and the data ultimately disappearing from the network.
Storj follows a similar approach to that of Sia, but instead of having the user take action to ensure sufficient erasure encoded file fragments are on the network, satellite nodes take over this job. Satellite nodes regularly execute data audits on the fragments stored on storage nodes. If an audit returns faulty fragments, the network will reconstruct the file, regenerate the missing pieces and store them back on the network.
For Arweave, consistent data redundancy is achieved through the Proof of Access algorithm that requires nodes to store older data to be able to mine newer data. This requirement means that nodes are incentivized to search and keep older and “rare” blocks, to increase their chances of being allowed to mine the next block and receive mining rewards.
Finally, Swarm ensures persistent redundancy by neighborhood replication as the key measure against data disappearing over time. Swam requires each set of nearest neighbors of a node to hold replicas of that nodes data chunks. Over time as nodes leave or join the network, these neighborhoods reorganize and each node’s nearest neighbors gets updated, requiring them to re-sync the data on their node. This leads to eventual data consistency. This is a continually ongoing process that is executed entirely off-chain.
Incentivizing Data Transmission

After users store data on a network, the data must also be retrievable when a user, another node, or a network process requests access to the data. After nodes receive and store data, they must be willing to transmit it when it is requested.
Filecoin achieves this through a separate type of miner called a retrieval miner. A retrieval miner is a miner that specializes in serving pieces of data and is rewarded in FIL tokens for doing so. Any user in the network can become a retrieval miner (including storage nodes), and retrieval orders are handled through the retrieval market. When a user wants to retrieve data, they place an order on the retrieval market, and retrieval nodes serve it. Although Filecoin is built on the same underlying stack as IPFS, Filecoin does not use IPFS’s Bitswap exchange protocol for transmitting user data. Instead, the Bitswap protocol is used to request and receive blocks for the Filecoin blockchain.
Crust directly uses IPFS’s Bitswap mechanism to retrieve data and motivate nodes to be willing to transmit data. In Bitswap, every node maintains credit and debt scores of nodes it communicates with. Nodes that only ask for data (for example when a user submits a data retrieval request) eventually have high enough debt that other nodes will stop reacting to its retrieval requests until it also starts to fulfill sufficient retrieval requests itself. Adding to this, in Crust Network the first four nodes that can provide proof of storage for data storage requests are awarded a proportion of the storage fees by the user that initiated the order, meaning that nodes benefit from being able to quickly receive data, which is contingent on how active they are in providing data. As a result, nodes are motivated to continuously fulfill data retrieval requests.
Swarm’s SWAP protocol (Swarm Account Protocol) works in the same fashion as IPFS’s Bitswap mechanism, with additional functionality integrated. Here also nodes maintain local databases of other nodes’ bandwidth credits and debts, creating a service-for-service relationship between nodes. However, SWAP assumes that sometimes there just isn’t data needed from one of the nodes to re-balance credit to debt ratio in the short term. To solve this, nodes can pay other nodes cheques to repay their debt. A cheque is an off-chain voucher that a node commits to pay another node, that can be redeemed for BZZ tokens through a smart contract on the Ethereum blockchain.
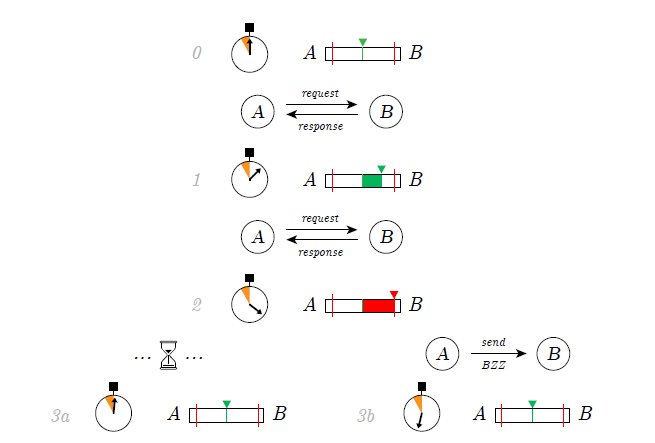
In both Sia and Storj, users pay for bandwidth that is used. In Sia, upload, download and repair bandwidth are paid by the user, while in Storj bandwidth required for upload is covered by the storage node. In Storj, this is meant to discourage nodes from deleting data immediately after it has been received. Due this set up, nodes have no reason to avoid using bandwidth, as bandwidth is paid for at a price they dictate before accepting storage orders.
Finally, in Arweave, nodes rationalize their bandwidth allocation based on how reliably a peer node shares transactions and blocks and how reliably it responds to requests. The node then keeps track of these factors for all peer nodes it interacts with, and preferably communicates with peer nodes that score higher. This promotes willingness for nodes to transfer data and share information, as receiving blocks in a slower fashion means they have less time compared to other nodes to solve the cryptographic hash puzzle of Arweave’s PoA consensus algorithm.
Tokenomics
Finally, networks must decide on a tokenomics design. While the above ensures data will be available whenever it should be available, tokenomics design ensures that the network will be around in the future. As without the network, there would be no underlying data for users and hosts to interact with. Here we will take a closer look at what tokens are used for and the factors that impact token supply.
Note: while all the above sections affect tokenomics design, here we primarily focus on token utility and token emissions design
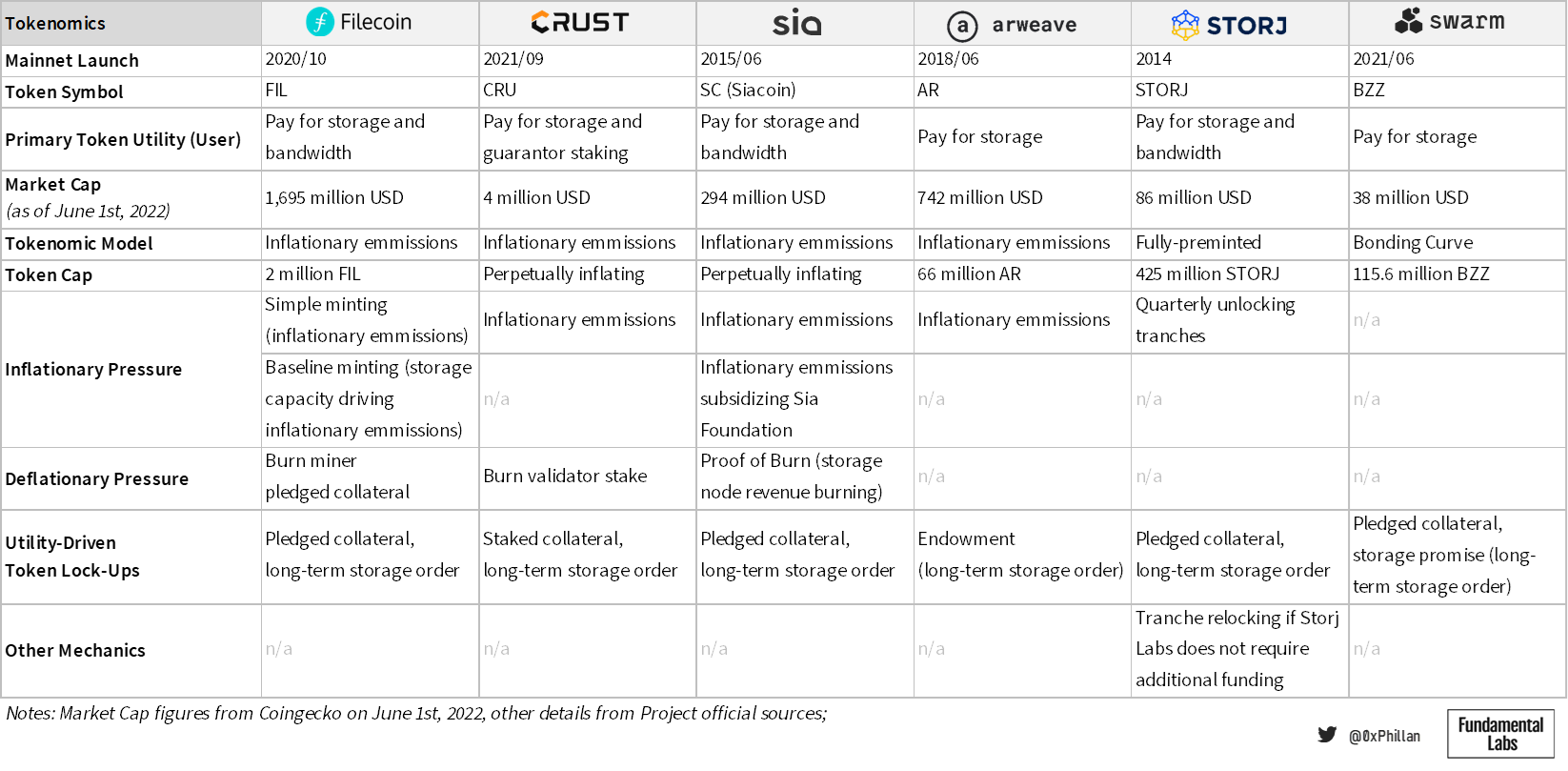
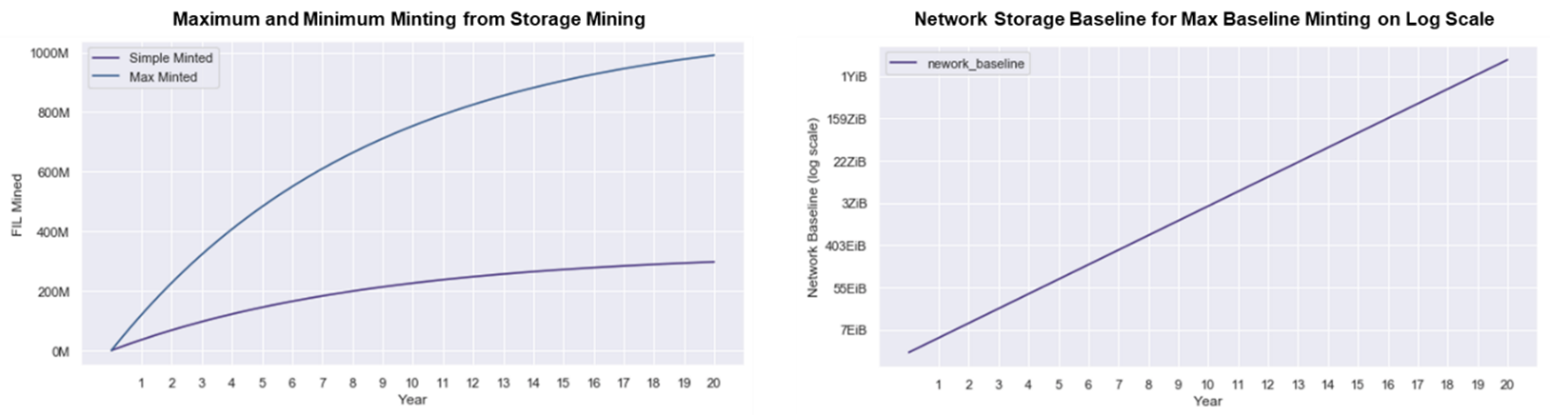
In the Filecoin network, the FIL token is used to pay for storage orders and retrieval bandwidth. The Filecoin network has an inflationary token emissions model using two types of minting: Simple minting, which emits new tokens as block rewards on a 6-year halving schedule (compared to Bitcoin’s 4 years) and baseline minting, which creates additional token emissions if the network reaches total storage space milestones (see figure 23). This means that storage miners on the network are incentivized to provide as much storage to the network as possible.
There are two ways that circulating supply of FIL on the market can be reduced. If miners fail to live up to their commitments, their pledged collateral is burned and permanently removed from the network (30.5 million FIL at time of writing). Finally, time-locked storage orders temporarily remove FIL from circulation and are paid out to miners over time. This means that the more storage is used, the fewer coins are in circulation in the short-term creating deflationary price pressure on the token value.
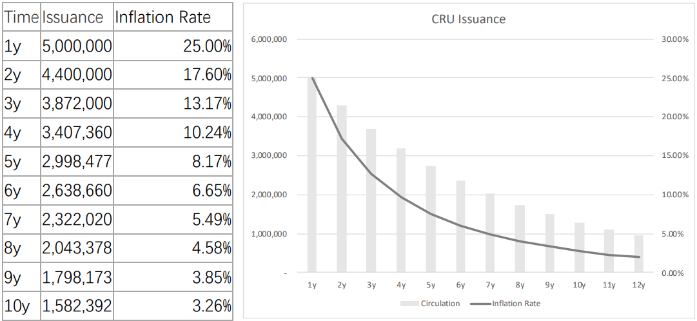
In Crust Network, the CRU token is used to pay for storage orders and used for staking as part of Crust Network’s Guaranteed Proof of Stake (GPoS) consensus mechanism. In this model, network token emissions are also inflationary and used as block rewards. Crust Network, however, does not have a token cap – for 12 years inflation is reduced YoY, after which token inflation continues perpetually at 2.8%.
In Crust, the stake a validator and its guarantors lock also acts as pledged collateral. If it is detected that a validator acts maliciously or is unable to provide the required proofs, their stake is slashed and burned. Finally, staked collateral and time-locked storage orders temporarily remove tokens from circulation. Since miner network storage capacity determines a miner’s staking limit, miners are incentivized to provide more storage capacity to maximize their staking income proportional to other miners. Staked tokens and tokens locked in time-locked storage orders create deflationary price pressure on the token value.
Sia has two coins that are used in the network; one is the utility coin Siacoin and the other is a revenue-generating coin called Siafunds. Siafunds were sold to the public when the network first went live, and are mostly held by the Sia Foundation. Siafunds entitle holders to a certain % of revenue for every storage order placed on the network. Siafunds do not have a substantial impact on the tokenomics of Sia and are hence not covered further here.
Siacoin has an inflationary token emissions model that act as block rewards, with no token cap. The block rewards perpetually decreased in a linear fashion per block until block height 270,000 (roughly 5 years of operation; reached in 2020). From then onwards, every block includes a fixed block reward of 30,000 SC. In 2021 the Sia Foundation hard-forked the Sia network to include an additional 30,000 SC subsidy per block to fund the Sia Foundation, a non-profit entity meant to support, develop, and promote the Sia network.
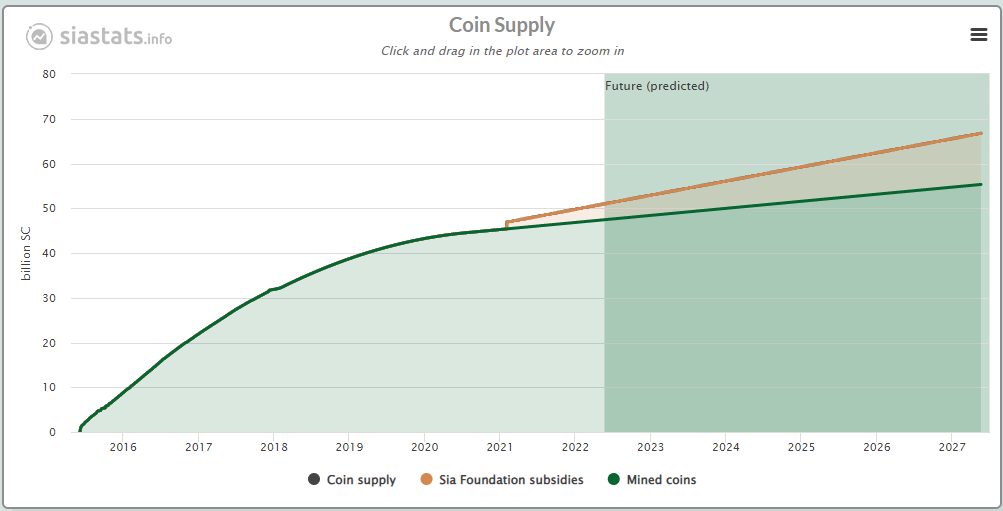
Sia also uses a Proof of Burn mechanism, that requires miners to burn 0.5-2.5% of their revenue to prove there are legitimate nodes on the network. This creates downward pressure on token supply, although annual burns only reflect roughly 500k SC compared to 3.14 billion SC of token emissions. Finally, pledged collateral and long-term storage orders also temporarily remove tokens from circulation in Sia.
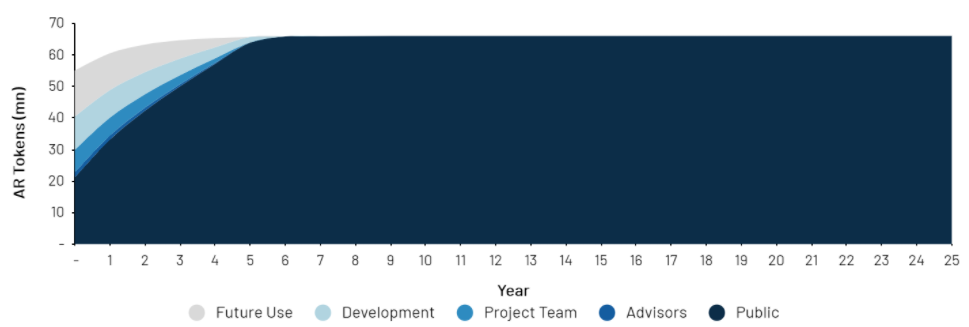
The Arweave network’s native token is the AR token, which is used to pay for perpetual and theoretically permanent storage on the Arweave network. Arweave also uses an inflationary token model, with a maximum supply cap of 66 million AR tokens. In Arweave, the primary deflationary impact is driven by Arweave’s endowments, which is Arweave’s implementation of a long-term storage contract. When a user wants to store files on Arweave, only a small amount of the storage fee goes to the miner – the rest is placed into an endowment which covers at least 200 years of storage time using Arweave’s highly conservative assumptions. That means, any storage order that is placed locks tokens away for at least 200 years, and is slowly paid out over this 200 year duration.
In Storj, the STORJ token is used to pay for storage and bandwidth. All 425 million STORJ tokens are pre-minted as ERC20 tokens on the Ethereum network. Previously, the Bitcoin-based SJCX token was used, however, in 2017 Storj Labs converted moved their tokens to Ethereum and renamed the ticker to STORJ. Of the STORJ tokens, currently 190.8 million STORJ tokens are locked up in six smart-contract controlled tranches in Storj Labs’ custody, while 234.1 million STORJ tokens are unlocked. Every quarter a tranche is unlocked, and when Storj Labs deems they do not need the funds to finance operations, they re-lock a tranche. This means that nearly half of STORJ supply is in direct control of Storj Labs, however, if they wanted to cash out they would have to wait 6 quarters, due to the funds being locked behind smart contracts. In Storj, pledged collateral by storage nodes and long-term storage orders also drive down circulating supply, as these tokens get temporarily locked-up.
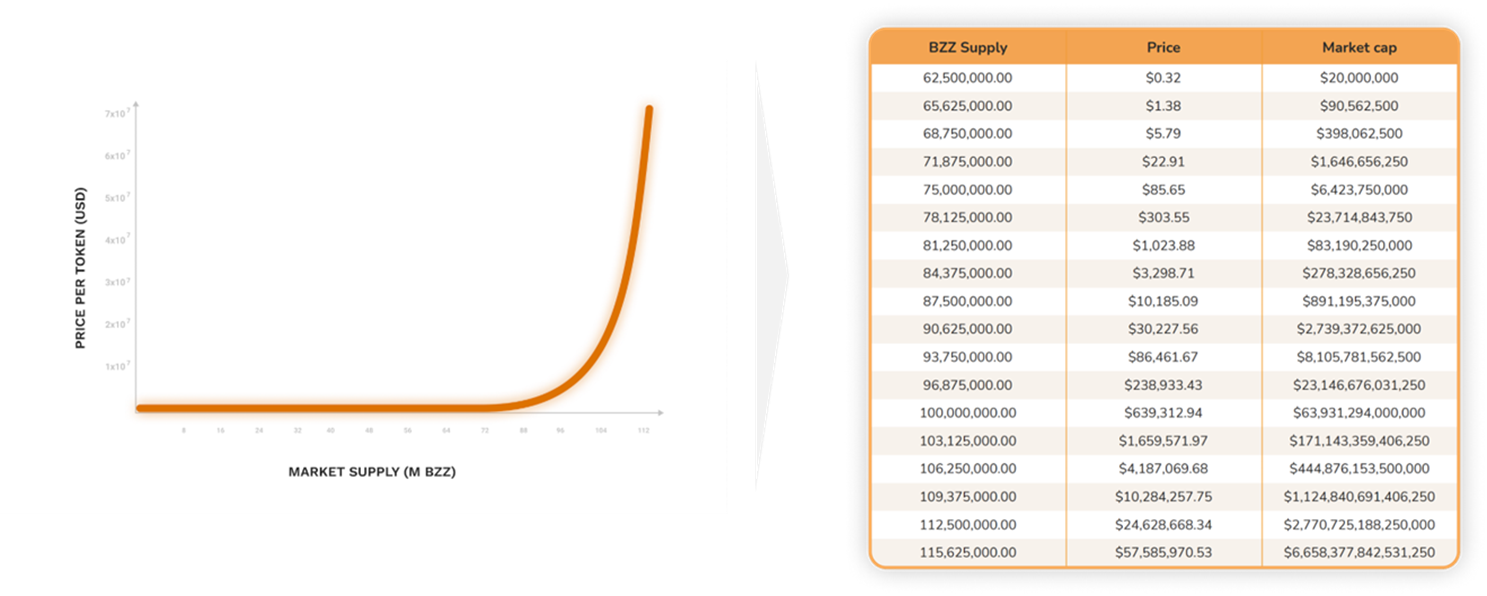
Finally, Swarm uses the BZZ token as a utility token to pay for storage on the network. The tokenomics model deployed by Swarm is a bonding curve, which determines the price of the token based on the supply thereof. Users can sell their tokens back to the bonding curve at any time at current market price. In Swarm, long-term storage orders require collateral to be pledged in the form of “promises”. Similar to the previous networks, more storage usage means fewer tokens available on the market, which would have deflationary pressures on the token price, as users who want to buy the token must purchase from the bonding curve, which will increase the price with every additional token sold.
Discussion
It is impossible to say that one network is objectively better than another. When designing a decentralized storage network, there are countless trade-offs that must be considered. While Arweave is great for permanent storage of data, Arweave is not necessarily suitable to move Web2.0 industry players to Web3.0 – not all data needs to be permanent. However, there is a strong sub-sector of data that does require permanence: NFTs and dApps.
If we look at other networks, we witness similar trade-offs: Filecoin is incentivizing Web2.0 storage providers to move their Storage to Web3.0 and is thus a driving a force in the adoption of decentralization. Filecoin’s Proof of Spacetime algorithm is computationally heavy with slow write speeds, which means that it is more suitable for higher-value data (like their slogan “storing humanity’s most important data”) that does not change often. However, many applications require constant changes to their data. Crust Network fills this gap by providing storage that is computationally less intensive to prove.
Looking at how these projects store data, we can see that Crust Network and Arweave are the only ones that do not use erasure encoding. One may think that erasure encoding is the better option, due to the majority of projects using it, but that is not necessarily the case. Arweave does not need erasure encoding, as the Proof of Access consensus mechanism paired with the Wildfire mechanic ensures data is replicated aggressively across the network. On Crust Network data is replicated to at least 20 nodes, and in many cases to over 100 nodes. While this does have greater up-front bandwidth, being able to retrieve data from a large number of nodes simultaneously makes file retrieval fast and adds strong redundancy in case of failures or nodes leaving the network. Crust Network needs this high level of redundancy, because it does not yet have a data replenishment or repair mechanism like the other chains. Of the decentralized storage networks reviewed here, Crust Network is the youngest.
If we compare any project to Filecoin, we will see other chains support a higher degree of storage decentralization, but may be more centralized in other aspects, such as Storj in which a single satellite node can control a large cluster of storage nodes. If that satellite node goes offline, all access to files is lost. However, having satellites control repair processes autonomously is a huge upgrade compared with the manual repair processes required in Sia. Storj also gives Web2.0 users an easier first step into decentralized storage, by allowing any form of payment between users and satellites.
If we further compare Storj’s approach to decentralization to that of the other projects, we will see that Storj’s lack of system-wide consensus is indeed a purposeful design decision to increase network performance, as the network does not need to wait on consensus to proceed with fulfilling storage requests.
Swarm and Storj are the only protocols that do not have their own layer1 blockchain network, and instead rely on ERC20 tokens deployed on the Ethereum network. Swarm is directly integrated in the Ethereum network, with storage orders being directly controlled through Ethereum smart contracts. This makes Swarm a strong choice for Ethereum native dApps and for storing the metadata of Ethereum-based NFTs, due to the convenience of proximity and same environment. Storj, while also based on Ethereum, is not that heavily integrated into the Ethereum ecosystem, however, can also benefit from smart contracts.
Sia and Filecoin use a storage market mechanism where storage providers can set their prices and are matched with storage users that are willing to pay those prices based on specific requirements, while in the other network storage pricing is protocol-dictated based on network-specific factors. Using a storage market means that users get greater choice regarding how their files are stored and secured but having the price set by the network reduces complexity and makes for an easier user experience.
There is no single best approach for the various challenges decentralized storage networks face. Depending on the purpose of the network and the problems it is attempting to solve, it must make trade-offs on both technical and tokenomics aspects of network design.

In the end, the purpose of the network and the specific use-cases it attempts to optimize will determine the various design decisions.
Comparative Network Profiling
What follows are summative profiles of the various storage networks comparing them amongst each other on a set of scales defined below. The scales used reflect comparative dimensions of these networks, however it should be noted that the approaches to overcome challenges of decentralized storage are in many cases not better or worse, but instead merely reflect design decisions.
- Storage parameter flexibility: the extent to which users have control over file storage parameters
- Storage permanence: the extent to which file storage can achieve theoretical permanence by the network (i.e., without intervention)
- Redundancy persistence: the networks ability to maintain data redundancy through replenishment or repair
- Data transmission incentivization: the extent to which the network ensures nodes generously transmit data
- Universality of storage tracking: the extent to which there is a consensus among nodes regarding the storage location of data
- Assured data accessibility: the ability of the network to ensure that a single actor in the storage process cannot remove access to files on the network
Higher scores indicate greater ability in each of the above.
Filecoin’s tokenomics support growing the total network’s storage space, which serves to store large amounts of data in an immutable fashion. Furthermore, their storage algorithm lends itself more to data that is unlikely to change much over time (cold storage).

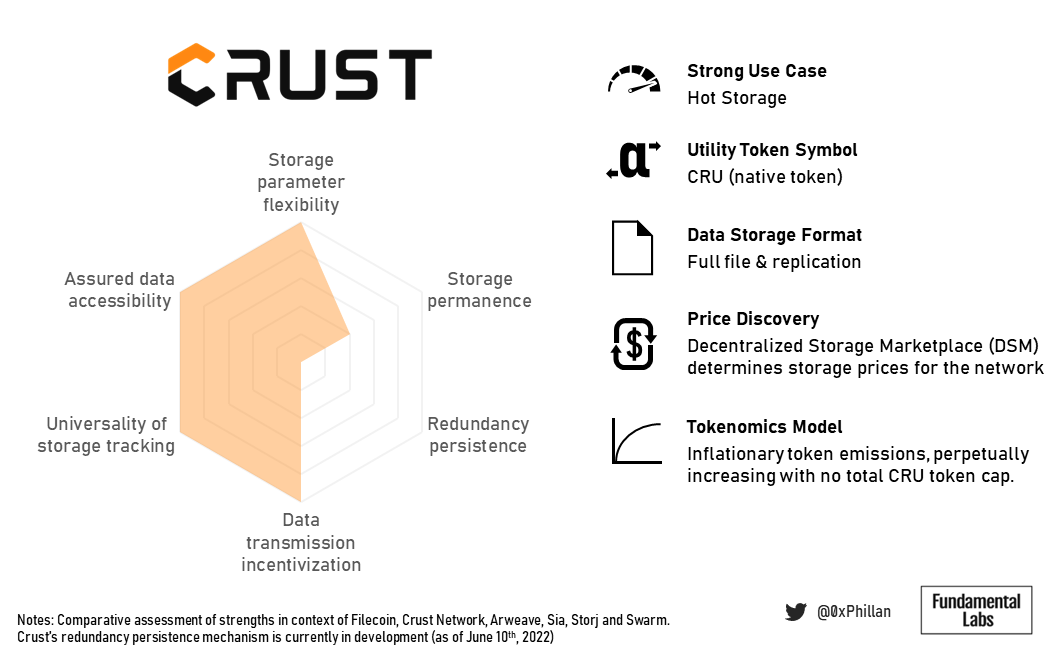
Crust’s tokenomics ensure hyper-redundancy with fast retrieval speeds which make it suitable for high traffic dApps and make it suitable for fast retrieval of data of popular NFTs.
Crust scores lower on storage permanence, as without persistent redundancy its ability to deliver permanent storage is heavily impacted. Nonetheless, permanence can still be achieved through manually setting an extremely high replication factor.
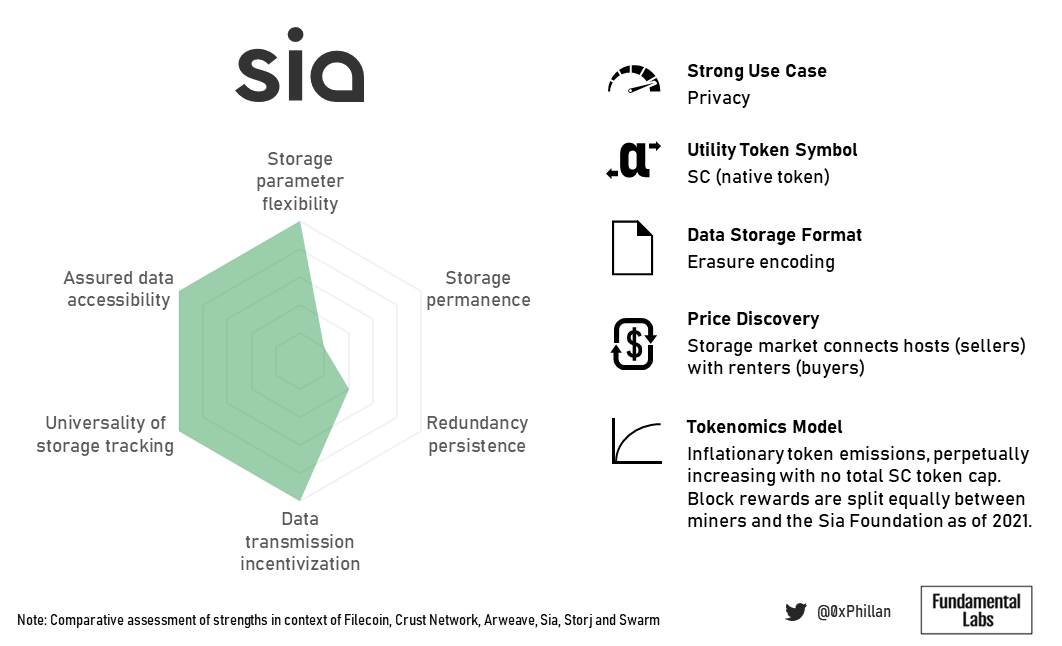
Sia is all about privacy. The reason manual health restoration by the user is required, is because nodes do not know what data fragments they are storing, and which data these fragments belong to. Only the data owner can reconstruct the original data from the fragments in the network.
In contrast, Arweave is all about permanence. That is also reflected in their endowment design, which makes storage more costly but also makes them a highly attractive choice for NFT storage.
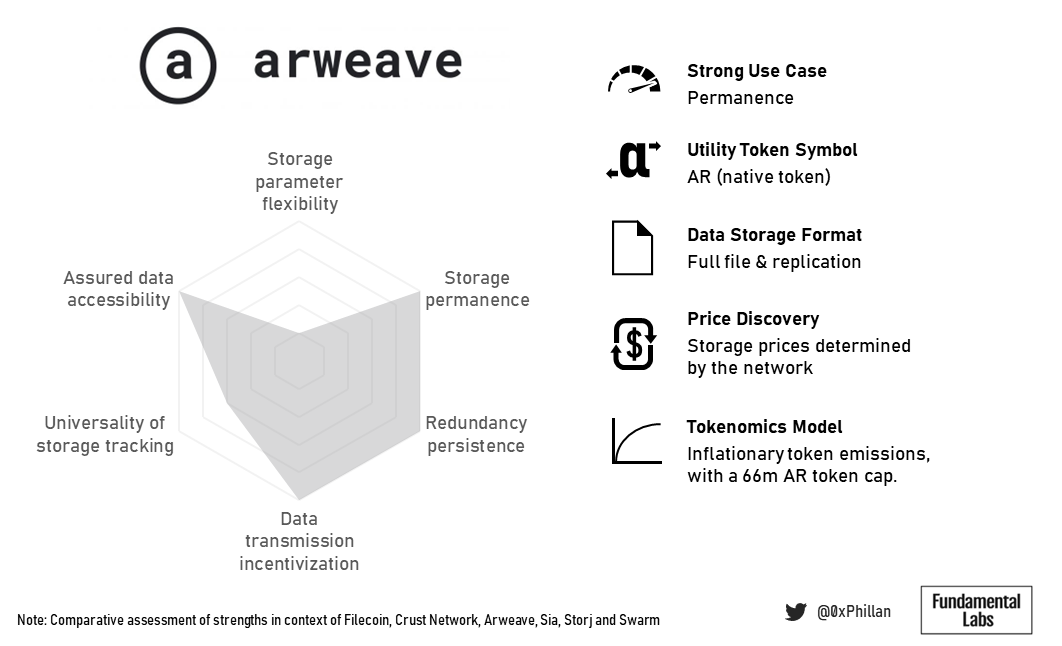
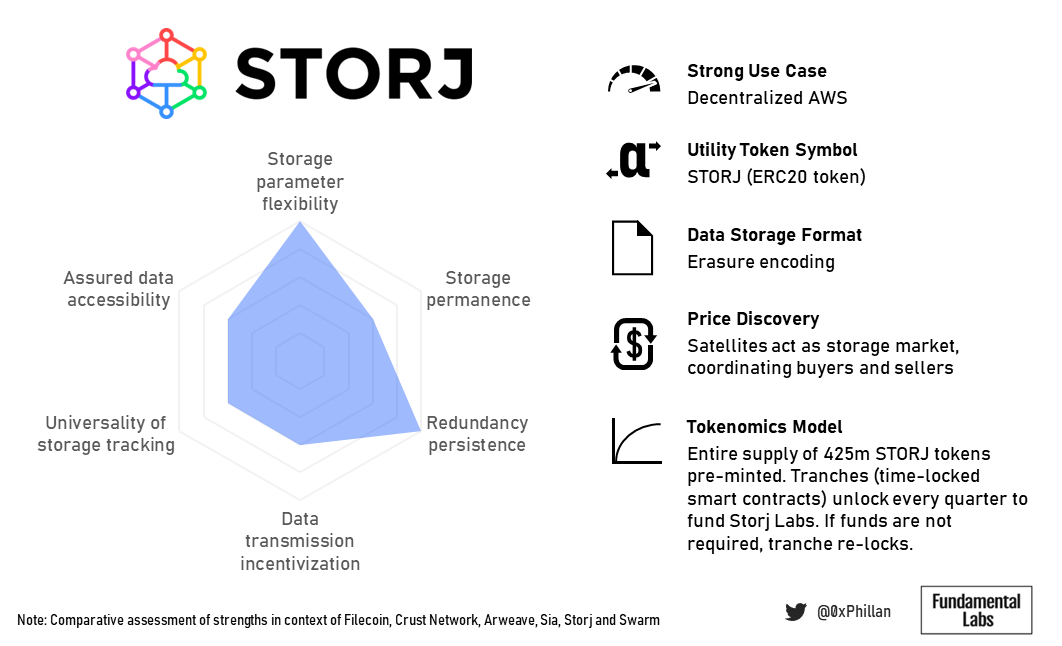
Storj’s business model seems to heavily factor in their billing and payment approach: Amazon AWS S3 users are more familiar with monthly billing. By removing complex payment and incentive systems often found in blockchain-based systems, Storj Labs sacrifices some decentralization but significantly reduces the barrier to entry for their key target group of AWS users.
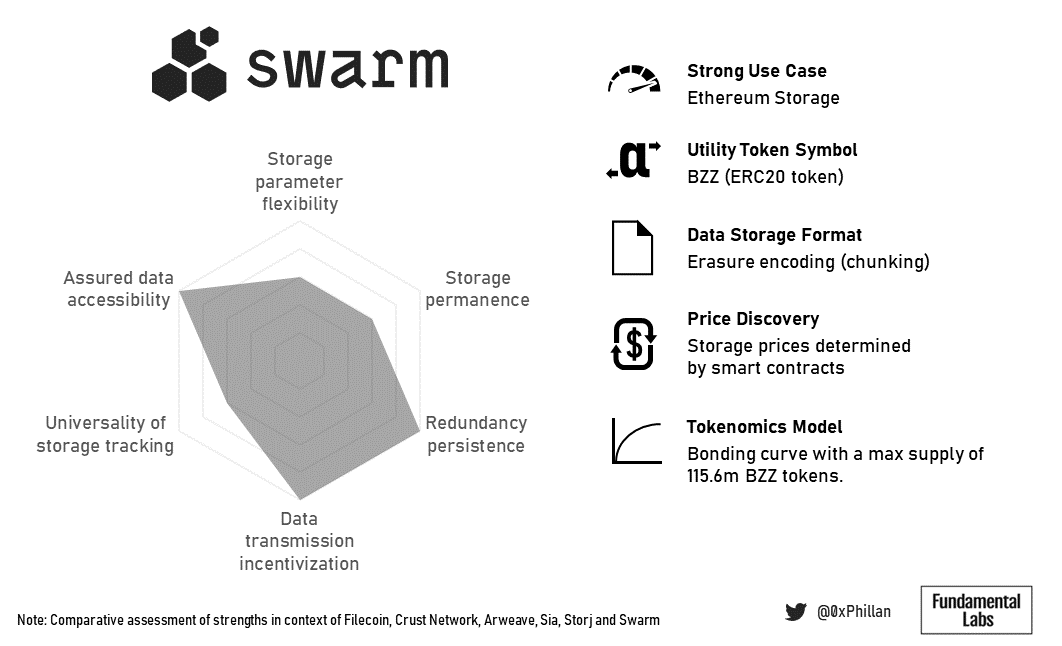
Swarm’s bonding curve model ensures storage costs remain relatively low overtime as more data is stored on the network, and its proximity to the Ethereum blockchain make it a strong contender to become the primary storage for more complex Ethereum-based dApps.
The next frontier
Returning to the Web3 infrastructural pillars (consensus, storage, computation), we see that the decentralized storage space has a handful of strong players that have positioned themselves within the market for their specific use cases. This does not exclude new networks from optimizing existing solutions or occupying new niches, but this does raise the question: what’s next?
The answer is: computation. The next frontier in achieving a truly decentralized internet is decentralized computation. Currently only few solutions exist that bring to market solutions for trustless, decentralized computation that can power complex dApps, which are capable of more complex computation at far lower cost than executing smart contracts on a blockchain.
Internet computer (ICP) and Holochain (HOLO) are networks that occupy a strong position in the decentralized computation market at time of writing. Nonetheless, the computational space is not nearly as crowded as the consensus and storage spaces. Hence, strong competitors are bound to enter the market sooner or later and position themselves accordingly. One such competitor is Stratos (STOS). Stratos offers a unique network design through its decentralized data mesh technology, combining blockchain technology with decentralized storage, decentralized computation and decentralized databases.
We see decentralized computation, and specifically the network design of the Stratos network, as areas for future research.
Closing
Thank you for reading this research piece on decentralized storage. If you enjoy research that seeks to uncover the fundamental building blocks of our shared Web3 future, consider following @FundamentalLabs on Twitter.
Did I miss any interesting concepts, or other valuable information? Please reach out to me on Twitter @0xPhillan so we can enhance this research together.
References
References have been split by category for easier review.
All references were accessed between May 5th and 31st, 2022.
Arweave
Amber Group (2011) Arweave: Enabling the Permaweb. Available at: https://medium.com/amber-group/arweave-enabling-the-permaweb-870ade28998b
Arweave (2021) Storage Endowment. Available at: https://arwiki.wiki/#/en/storage-endowment (Accessed May 29th, 2022)
Arweave (2021) What is the Permaweb. Available at: https://arwiki.wiki/#/en/the-permaweb (Accessed May 29th, 2022)
Arweave (2022) Storage Price Stabilization. Available at: https://arwiki.wiki/#/en/Storage-Price-Stabilization (Accessed May 29th, 2022)
Arweave (n.d.) Technology. Available at: https://www.arweave.org/technology
Arweave Fees (2021) Arweave Fees. Available at: https://arweavefees.com/
Crypto Valley Journal (n.d.) Permaweb. Available at: https://cvj.ch/en/glossary/permaweb/
Gemini (2022) Arweave: A Permanent, Decentralized Internet. Available at: https://www.gemini.com/cryptopedia/arweave-token-ar-coin-permaweb
Gemini (n.d.) Glossary: Permaweb. Available at: https://www.gemini.com/cryptopedia/glossary#permaweb
Messari (n.d.) Arweave – Data Storage Protocol. Available at: https://messari.io/asset/arweave/profile/token-usage
Tom McWright (2019) How much does Arweave cost? https://observablehq.com/@tmcw/how-much-does-arweave-cost
Wayne Jones (n.d.) Can data really be stored forever? Available at: https://ardrive.io/can-data-really-be-stored-forever/
Crust
Crust Network (2020) Crust Technical White Paper v1.9.9. Available at: https://gw.crustapps.net/ipfs/QmP9WqDYhreSuv5KJWzWVKZXJ4hc7y9fUdwC4u23SmqL6t
Crust Network (2021) Crust Token Metrics & Economies. Available at: https://medium.com/crustnetwork/crust-token-metrics-economics-84592efc6d1f
Crust Network (2021) Economy Whitepaper. Available at: https://gw.crustapps.net/ipfs/QmRYJN6V5BzwnXp7A2Avcp5WXkgzyunQwqP3Es2Q789phF
Crust Network (n.d.) DSM. Available at: https://wiki.crust.network/docs/en/DSM
Crust Network Subscan (n.d.) Storage Price Calculator. Available at: https://crust.subscan.io/tools/storage_calculator
Filecoin
Coinlist (2017) Filecoin Token Sale Economies. Available at: https://coinlist.co/assets/index/filecoin_2017_index/Filecoin-Sale-Economics-e3f703f8cd5f644aecd7ae3860ce932064ce014dd60de115d67ff1e9047ffa8e.pdf
File.App (n.d.) Available at: https://file.app/
Filecoin (2020) Date Transfer in Filecoin. Available at: https://spec.filecoin.io/systems/filecoin_files/data_transfer/
Filecoin (2020) Storage Market in Filecoin. Available at: https://spec.Filecoin.io/systems/Filecoin_markets/storage_market/
Filecoin (2020) Understanding Filecoin Circulating Supply. Available at: https://filecoin.io/blog/filecoin-circulating-supply/
Filecoin (2020) What sets it apart: Filecoin’s proof system. Available at: https://filecoin.io/blog/posts/what-sets-us-apart-filecoin-s-proof-system/
Filecoin (2021) How storage and retrieval deals work on Filecoin. https://Filecoin.io/blog/posts/how-storage-and-retrieval-deals-work-on-Filecoin/
Filecoin (n.d.) IPFS and Filecoin. Available at: https://docs.Filecoin.io/about-Filecoin/ipfs-and-Filecoin/
Filecoin (n.d.) IPFS. Available at: https://spec.filecoin.io/#section-libraries.ipfs
James Duade (2021) FileCoin: Decentralized Cloud Storage Competitor To AWS, Microsoft Azure, And Google Cloud. Available at: https://seekingalpha.com/article/4419553-Filecoin-decentralized-cloud-storage-competitor-aws-microsoft-google
IPFS
Brave (2021) IPFS Support in Brave. Available at: https://brave.com/ipfs-support/
Hussein Nasser (2021) The IPFS Protocol Explained with Examples – Welcome to the Decentralized Web. Available at: https://www.youtube.com/watch?v=PlvMGpQnqOM
IPFS (n.d.) InterPlanetary Name System (IPNS). Available at: https://docs.ipfs.io/concepts/ipns/
James (2018) The technology behind IPFS. Available at: https://medium.com/coinmonks/the-technology-behind-ipfs-and-what-can-ipfs-do-c7009fe42bab
Sia
Cryptopedia Staff (2021) Sia: A Highly Decentralized Data Storage Solution. Available at: https://www.gemini.com/cryptopedia/siacoin-mining-sia-crypto-sc-coin-decentralized-storage#section-siacoin-sc-and-siafunds
Sia Docs (2022) Sia 101. Available at: https://docs.sia.tech/get-started-with-sia/sia101
Sia Wiki (2017) Hosting. Available at: https://siawiki.tech/host/hosting
Sia Wiki (2017). Using the UI for renting. Available at: https://siawiki.tech/renter/using_the_ui_for_renting
SiaStats.info (2018) “When coin burn?” Every day, and 400 000 SC so far. Available at: https://www.reddit.com/r/siacoin/comments/8te2e4/when_coin_burn_every_day_and_400_000_sc_so_far/
Taek (2015) [ANN] Sia – Decentralized Storage. Available at: https://bitcointalk.org/index.php?topic=1060294.msg11372055#msg11372055
Taek (n.d.) How Sia Works. Available at: https://web.archive.org/web/20171102065557/https:/forum.sia.tech/topic/108/how-sia-works
Vorick, D. and Champine, L. (2014) Sia: Simple Decentralized Storage. Available at: https://sia.tech/sia.pdf
Storj
Gleeson, J. (2019) Cloud Storage Prices Haven’t Changed Much in 4 Years but They’re About To. Available at: https://www.storj.io/blog/cloud-storage-prices-havent-changed-much-in-4-years-but-theyre-about-to
Gleeson, J. and Ihnatiuk, V. (2021). Sharing Space for Fun and Profit—Part 2. Available at: https://www.storj.io/blog/sharing-space-for-fun-and-profit-part-2
Johnson, K. (2022) STORJ Token Balances and Flows Report: Q1 2022. Available at: https://www.storj.io/blog/storj-token-balances-and-flows-report-q1-2022
Storj DCS Docs (n.d.) Getting Started on DCS. Available at: https://storj-labs.gitbook.io/dcs/
Storj Docs (n.d.) Billing, Payment and Accounts. Available at: https://docs.storj.io/dcs/billing-payment-and-accounts-1/pricing/
Storj Forum (2020) Single point of Failure if a Satellite is down? Available at: https://forum.storj.io/t/single-point-of-failure-if-a-satellite-is-down/4577
Storj Labs (n.d.) Transparent Pricing. Available at: https://www.storj.io/pricing
Storj Labs, Inc (2018) Storj: A Decentralized Cloud Storage Network Framework. Available at: https://www.storj.io/storjv3.pdf
Storj Labs, Inc and Subsidiaries (2018) V3 White Paper Executive Summary. Available at: https://www.storj.io/Storj-White-Paper-Executive-Summary.pdf
Storj Nlog (2019) What Storage Node Operators Need to Know About Satellites. Available at: https://www.storj.io/blog/what-storage-node-operators-need-to-know-about-satellites
Swarm
Altcoin Disrupt (2021) What is Swarm? ICO Upcoming? Will Swarm 100X? Decentralized? $10K – $100K. Available at: https://www.youtube.com/watch?v=rxPlYf9Pe2A
Coding Bootcamps (n.d.) How to Work with Ethereum Swarm Storage. Available at: https://www.coding-bootcamps.com/blog/how-to-work-with-ethereum-swarm-storage.html
ETHDenver (2022) The State Of Ethereum Swarm – Angela Vitzthum. Available at: https://www.youtube.com/watch?v=22HfkeEmOK4
Ethereum Wiki (2020) Swarm Hash. Available at: https://eth.wiki/concepts/swarm-hash
Munair (2021) A Case for Swarming Medical History. Available at: https://munair.medium.com/a-case-for-swarming-medical-history-77baa5e40424
Swarm (n.d.) Swarm Docs. Available at: https://docs.ethswarm.org/docs/
Swarm Hive (2021) BZZ Tokenomics. Available at: https://medium.com/ethereum-swarm/swarm-tokenomics-91254cd5adf
Swarm Hive (2021) Swarm and its “Bzzaar” Bonding Curve. Available at: https://medium.com/ethereum-swarm/swarm-and-its-bzzaar-bonding-curve-ac2fa9889914
Swarm team (2021) SWARM: Storage and communication infrastructure for a self-sovereign digital society. Available at: https://www.ethswarm.org/swarm-whitepaper.pdf
Thebojda (2022) A Brief Introduction to Ethereum Swarm. Available at: https://hackernoon.com/a-brief-introduction-to-ethereum-swarm
Trón, V. (2021) The book of Swarm: storage and communication infrastructure for self-sovereign digital society back-end stack for the decentralised web. V1.0 pre-release 7. Available at: https://www.ethswarm.org/The-Book-of-Swarm.pdf
Miscellaneous
BitcoinFees.net (n.d.) Bitcoin Fees. Available at: https://bitcoinfees.net/ (Accessed May 15th, 2022)
BitcoinTalk Forum (2021) Some questions about OP_Return. Available at: https://bitcointalk.org/index.php?topic=5310671.0
Daniel, E. and Tschorsch, F. (2022) IPFS and Friends: A Qualitative Comparison of Next Generation Peer-to-Peer Data Networks. Available at: https://arxiv.org/pdf/2102.12737.pdf
Dfinity (n.d.) Blockchain’s future. Available at: https://dfinity.org/
Dr. Wood, G. (2016) Ethereum: A Secure Decentralized Generalised Transaction Ledger EIP-150 Revision. Available at: http://gavwood.com/paper.pdf
Ethereum Foundation (2022) Gas and Fees. Available at: https://ethereum.org/en/developers/docs/gas/
Ethereum Foundation (2022) Introduction to Dapps. Available at: https://ethereum.org/en/developers/docs/dapps/
Etherscan (2021) CryptopunksData Smart Contract. Available at: https://etherscan.io/address/0x16f5a35647d6f03d5d3da7b35409d65ba03af3b2#code
Fenbushi Capital (2021) Stratos: build “convenience store” network for decentralized storage. Available at: https://fenbushi.medium.com/stratos-build-convenience-store-network-for-decentralized-storage-7cd7dd0d2b49
Georgios Konstantopoulos & Leo Zhang (2021) Ethereum Blockspace – Who Gets What and Why. Available at: https://research.paradigm.xyz/ethereum-blockspace
Internet Computer (2022) Computation and Storage Costs. Available at: https://internetcomputer.org/docs/current/developer-docs/deploy/computation-and-storage-costs
Kofi Kufuor (2021) The State of NFT Data Storage. Available at: https://thecontrol.co/the-state-of-nft-data-storage-c471c1af58d5
Larva Labs (2021) On-chain Cryptopunks. Available at: https://www.larvalabs.com/blog/2021-8-18-18-0/on-chain-cryptopunks
SnapFingersEditor (2021) Decentral Storage for NFTs | SnapFingers Weekly #9. Available at: https://medium.com/snapfingers/decentral-storage-for-nfts-snapfingers-weekly-9-2d9315320847
Stackexchange Forum Bitcoin (2015) Explanation of what an OP_RETURN transaction looks like. Available at: https://bitcoin.stackexchange.com/questions/29554/explanation-of-what-an-op-return-transaction-looks-like (Accessed May 15th, 2022)
Stackexchange Forum Ethereum (2016) What is the cost to store 1KB, 10KB, 100KB worth of data into the ethereum blockchain? Available at: https://ethereum.stackexchange.com/questions/872/what-is-the-cost-to-store-1kb-10kb-100kb-worth-of-data-into-the-ethereum-block
Uniswap (2020) Uniswap Interface + IPFS. Available at: https://uniswap.org/blog/ipfs-uniswap-interface
Uniswap (2022) Uniswap Frontend Interface Release on Github. Available at: https://github.com/Uniswap/interface/blob/main/.github/workflows/release.yaml
Uniswap (2022) Uniswap Github Code Repository. Available at: https://github.com/Uniswap/interface
SHARE THIS PIECE
Related content

In this piece @lingchenjaneliu explores the staking market landscape, including key actors and top players, as well as latest developments in Proof-of-Stake. Special thanks to @0xPhillan for ...

The year of 2022 was a year of great highs and new lows for the Web3 industry. Read more about the defining events of 2022!

Metaverse Concept and History The term "metaverse" was invented by American author Neal Stephenson in his science fiction novel titled Snow Crash, published in 1992. ...

Short answer: Account abstraction creates a new account type which exists as a smart contract. By having the account exist as a smart contract, transaction ...